Schemas
Para entender de maneira simples o que é um SCHEMA no Banco de Dados Oracle, podemos resumir que um schema é um usuário e tudo que tem dentro dele.
O schema é criado automaticamente, quando um usuário é criado, embora possa ser criado através do comando CREATE SCHEMA. Dentro desta estrutura lógica ficam tabelas, procedures, índices entre outros objetos. E cada schema pertence apenas a seu usuário. Segue lista de objetos que fazem parte de um schema.
- Analytic views
- Attribute dimensions
- Clusters
- Constraints
- Database links
- Database triggers
- Dimensions
- External procedure libraries
- Hierarchies
- Index-organized tables
- Indexes
- Indextypes
- Java classes
- Java resources
- Java sources
- Join groups
- Materialized views
- Materialized view logs
- Mining models
- Object tables
- Object types
- Object views
- Operators
- Packages
- Sequences
- Stored functions
- Stored procedures
- Synonyms
- Tables
- Views
- Zone maps
Embora muitas estruturas sejam armazenadas logicamente dentro de um schema, existem objetos que não fazem parte de um schema, tais objetos são os seguintes:
- Contexts
- Directories
- Editions
- Flashback archives
- Lockdown profiles
- Profiles
- Restore points
- Roles
- Rollback segments
- Tablespaces
- Tablespace sets
- Unified audit policies
- Users
Schemas Sample
Os schemas sample são estruturas disponibilizadas pela Oracle como exemplos, nela temos usuários, tabelas, índices, constraints, preenchidos com informações, o que torna possível aprender SQL utilizando os mesmos, pois é possível aplicar os conceitos de SQL, manipulando esses dados, criando joins entre as tabelas, testando o funcionamento de funções, enfim, um banco de dados completo e pronto para o uso. A familiaridade com esses schemas dummies, ajuda até mesmo nas provas de certificações da Oracle, visto que esses são utilizados nas questões, logo conhecendo a estrutura dos mesmo pode ajudar na hora da prova, onde se tem muitas questões e pouco tempo para pensar.
- HR Schema (Human Resources) -
- usado para tópicos de introdução ao SQL básico;
- OE Schema (Order Entry)
- usado para tópicos de dificuldade intermediária, possui mais tipos de dados;
- OC Schema (Online Catalog)
- é uma coleção de objetos relacionais do utilizado no schema OE.
- PM Schema (Product Media)
- dedicado para dados do tipo mídia;
- CO Schema (Customer Orders)
- é um schema moderno que possui demostrações de transações de e-commerce, permitindando armarzenar dados semi-estruturados usando JSON;
- IX Schema (Information Exchange)
- é um conjunto de schemas, usado para demonstrar as capacidades avançadas de consultas Oracle;
- SH Schema (Sales History)
- desenvolvido para demonstrar grandes quantidades de dados, possui suporte para processamento analítico.
Até a versão 12 do banco do dados Oracle, era possível incluir a instalação desses schemas juntamente com a instalação do banco, nas versões mais recentes é necessário a instalação manualmente após o banco estar devidamente instalado.
Maiores detalhes a respeito de cada um dos schemas de exemplo podem ser encontradas neste link.
Para obter os samples schemas é necessário o download através do GitHub, disponível nesse link.
Instalando o Schema HR
Como dito anteriormente, nas versões antigas do Oracle Database era possível definir a instalação dos schemas durante a instalação da aplicação, nas versões acima de 18c não temos essa opção, contudo, o schema HR fica disponível na instalação do Oracle Database no caminho: '$ORACLE_HOME/demo/schema/human_resources'.
Após acessar o diretório onde se encontra os arquivos de instalação do schema, devemos acessar o SQLPlus utilizando um usuário com privilégios de administrador, podemos utilizar o comando abaixo para tal ação.
$ sqlplus connect sys as sysdba
Logo em seguida devemos executar o script hr_main.sql que contém os passos automatizados da instalação.
SQL> @?/demo/schema/human_resources/hr_main.sql
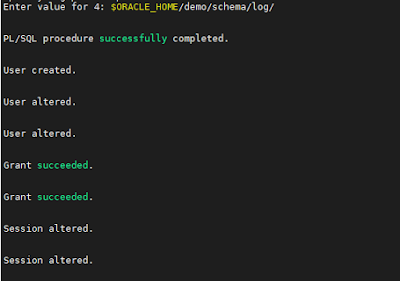
Assim que o script for inicializado, serão apresentados prompts solicitando a inclusão de argumentos, na seguinte ordem:
- Senha para o usuário HR;
- Default tablespace para o schema HR;
- Tablespace temporário para o schema HR;
- Senha do usuário sys;
- Diretório de log.
Seguido das informações solicitadas, é necessário aguardar finalizar a instalação.
Assim que concluir a instalação devem ser verificados os logs para validação da instalação, em alguns casos podem ocorrer erros na criação do usuário HR, nesse caso, o restante da instalação também irá falhar, o erro pode estar relacionado com o tipo de sessão do usuário sys, nesse caso é necessário alterar o tipo de sessão para que e reexecutar o script para que seja concluído com sucesso. 
$ alter session set "_ORACLE_SCRIPT"=true;
Após a alteração da sessão, a instalação corre conforme o esperado.
E por fim temos schema devidamente instalado.
Para um detalhamento de todas as ações realizadas pelo script de instalação a Oracle disponibiliza essas informações nessa página.
Schema HR
O schema HR mostra uma estrutura de recursos humanos de uma empresa, se divide nas seguintes tabelas:
- EMPLOYEES
- JOBS
- JOB_HISTORY
- DEPARTMENTS
- LOCATIONS
- REGIONS
- COUNTRIES
Segue abaixo modelo de dados do schema HR.
Finalmente com o ambiente completamente finalizado mãos a obra!
Fontes:
https://docs.oracle.com/en/database/oracle/oracle-database/19/comsc/index.html
https://docs.oracle.com/en/database/oracle/oracle-database/19/comsc/HR-sample-schema-scripts-and-objects.html
https://docs.oracle.com/database/121/COMSC/scripts.htm#COMSC00021
https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/Database-Objects.html#GUID-31BE00A7-7FF9-41CB-852A-F1416912CA9E